



At our last meeting, there were a couple of public comments from colleagues about the machine-generated transcript I posted along with the video of the June 25, 2025 Citizens Advisory Board meeting. Long-time readers know I usually turn the other cheek on personal attacks.
But information science, and particularly voice recognition was my thing in school. So permit me to nerd out for a few minutes on how these transcripts are generated.
As I grow deafer and blinder, I let machines do more work for me—including machine-generated transcriptions. I don’t trust them, but it’s a valuable tool for me, occasional errors and all, and it’s also interesting watching them improve. I share them with you, like all sorts of experiments on this web site (eg. translations and feeds from other sites like KCLS) in the same spirit as me Gran, “It’s not great. But it’s better than not having it.” 😀 I post disclaimers and I only share with people who subscribe to my ‘feeds’.
Also, I don’t watch long videos these days unless I’m trying to figure out how to fix a transmission. Or if it involves sport or the Marvel Cinematic Universe.
And I think you agree with me. I get a surprising number of “thank yous” when I posted transcripts. I also notice that those posts generate more clicks. Both are nice. 🙂
What I hadn’t heard—until this week—were complaints about accuracy. Perhaps because, if you’ve opened more than one machine-generated transcript (or translation service – which is what they really are), you know what to expect. They’re getting better, but they still make errors—including the ones from chronic purveyors of misinformation like Highline Schools or TVW, the recording system used by the State of Washington.
They make no apologies. They don’t go back and hand-edit mistakes for the sake of Duty and Humanity! And neither do I. 🙂
How it works… or not…
They (and I) could use a very expensive, time-consuming system. Or we can use inexpensive, or even free tools, which middle-schoolers can access, because all of them now get 99% of the text correct. Guess which one I choose? 😀
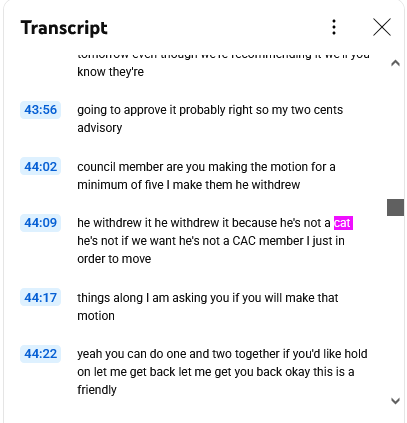
Why is it free? Well because it doesn’t “hear” or “listen.” It just reads the text that YouTube or other video providers already generate. Like so…
There was outrage that the Mayor would ever use the word cat. Maybe she did or did not say ‘cat’ at 44:09. But I would note that it got “CAC” and “CAB” right, over 100 times.
Speaker Names
The only ‘innovation’ is that, as it reads in the text, my tool tries to figure out who is speaking. Mostly it gets it right. Sometimes it gets it wrong. Apparently that caused even bigger outrage, perhaps because it failed to identify the Deputy Mayor.
He shouldn’t take it personally. That is directly related to why it got tons of things wrong in this particular transcript.
Ever notice how, when a member of the City staff gets up to speak they always identify themselves? They are trained to do that, even though we all know them. But at the CAB meeting, the Deputy Mayor did not introduce himself. Ironically, he asked everyone else to introduce themselves—which is why it recognized them, and not him. But it had no idea where to start. He didn’t follow his own rule! And it was all down hill from there.
Again, the freebie model renders text remarkably accurately. It’s even kind—- filtering out most of the repeated words, likes, ums, and ya knows that make all of us read as idiots.
And then, of course, people talked over one another a lot. They often didn’t use their mic switches. In short, they behaved like any normal group of people at our City Hall – except for staff – the only people paid to follow the correct protocol. 😀 Always introduce yourself. Always hit the mic.
To my mind, the AI universe may have been sending us a gentle message from beyond the Ethernet. In addition to better protocol, after twenty years, maybe fix the microphone situation once and for all? 😀
One other thing: the YouTube feed mentions people I’ve never met, including Tracy Buckton and Jean Oxinger. Because, as with ‘cat’, that is what the audio sounds like. But from previous transcripts my AI has learned who Gene Achziger and Traci Buxton are, in spite of what people actually say.
However, it couldn’t know that Eileen is Aileen, or that Lynn is Lin. It does now. It just needs chances to try, fail, apply corrections, and learn. That’s the public experiment I’m running. Don’t like it? Don’t watch. 🙂
Grace…
What could I have done better? First of all, whenever anyone finds a true error of fact (like a wrong number or a true misquote) on the web site, I fix it. End of story.
But to my mind, transcription is fundamentally different.
What it is not is a budget document or an ordinance, or an equation or any other unambiguous source of truth. At this point in history, it’s a convenience, again like the translation widget, I started using a few years ago – which the City now uses as well. It used to suuuuuuuuuuck. Now it sucks less. But also again, it’s better than not having it. It’s an experiment I’m willing to run in public. And in return it will get to higher accuracy. I hope you feel the same.
Why machines can be good
But I mentioned correction. And there is a bit of magic one can do to accelerate that process many times over. It’s called ‘please’. When people point these things out to me nicely, in person, instead of using a public forum to get all outraged about ‘!!!misinformation!!!’, it works ever so much better. At least with me. 🙂
Here is how I talk to my AI.
As usual you got a -lot- right, but you also made several errors. If you still have your original work cached I need a redo: the opening speaker was Deputy Mayor Harry Steinmetz who presided over the meeting and thus speaks most often, although he did not identify himself. You seemed to conflate several speeches, anecdotally, it seems most often where he interacts with other speakers. Also, it’s Barton DeLacy. Eileen is Aileen. Gance is Gantz, Harpi Cow is Harpreet Kaur, and Lynn Cashman is Lin Cashman. Hit it.
I did that just now and it’s better. But like the translation widget, it is still likely nowhere perfect. Yet. What I do not do is ‘edit’. I give it the right ‘cues’, at the right times, and it learns. Permanently. I don’t think most people have internalised this.
If people want better transcription services? Feel free to pay for them! 🙂
But this AI has already learned never to say Oxinger instead of Achziger or Delridge instead of Delrose or dozens of other faux pas – as some of my colleagues do – over and over, year after year, and on camera. Some might consider that fairly disrespectful as well.
Instead, it simply fixes the problem, not the blame, and moves on.